- a new Tool Provided by a Network of Libraries
Citation metrics are a well-established means to assess the impact of scholarly output. With the growing availability of e-journals, usage metrics have become an interesting alternative to citation metrics; they allow for viewing scholarly communication from the user's perspective. Usage metrics offer several advantages that have the potential of enhancing existing evaluation criteria for scholarly journals.
This paper suggests an approach to providing global usage metrics which is supported by libraries. The goal is to provide an analytical tool called Standardized Electronic Resource Usage Metrics (SERUM) which is comparable to the Journal Citation Reports (JCR), but which makes use of download data instead of citation data.
Global download data would be obtained from the publishers, assuming they are willing to contribute in order to benefit from newly established evaluation criteria for periodicals beyond the Journal Impact Factor (JIF) and consequential strengthening of their products. An international network of libraries with a sound disciplinary coverage will be established in order to obtain, manage and check the authenticity of the data delivered by the publishers. The network will act as a clearing centre operated by independent information specialists to guarantee data integrity as well as data curation according to a standardised format. Furthermore, the network's internationally distributed members should also track and manage local usage data, reflect local trends, and relate these to the global publishers' data. In addition, a regularly updated version with specific basic usage metrics and journal rankings will be offered.
In 1927 the Gross brothers introduced the system whereby the total number of citations (excluding journal self-citations) are used to identify the most relevant journals in a research area (Gross and Gross, 1927). For the first time citations were used as a collection management instrument. Before that time, library acquisitions departments relied mainly on usage data. But tracking physical usage was a cumbersome and difficult task. The data obtained in this way were usually combined with information obtained from user surveys, although these surveys were always perceived as time-consuming as well as annoying for the library users. Document demand patterns apparent from document delivery services were also used for decision making in academic librarianship; the relationship between the most requested and the most cited journals was studied e.g. by Schloegl & Gorraiz (Schoelgl and Gorraiz, 2006). The introduction of the Science Citation Index by Garfield in 1964 laid the foundation for a whole new discipline called scientometrics. In 1972 Garfield published his article ‘Citation analysis as a tool in journal evaluation’ in Science and it attracted a great deal of attention from journal editors (Garfield, 1972). Three years later Garfield launched the first edition of the ‘Journal Citation Reports’ offering global journal rankings. This tool, initially called ‘a bibliometric analysis of science journals in the ISI database’, introduced the following citation metrics:
-
Total cites: as a measure for the citation quantity
-
Impact factor: as a measure for the average citation frequency
-
Immediacy index: as a measure for the citation speed
-
Cited/citing half-life: as a measure for the ageing characteristics of a subject field.
Meanwhile, citation metrics have become well established (especially in Science, Technology and Medicine) and their benefits are clearly promoted by Thomson Reuters' JCR for the different target groups:
-
Librarians can manage and maintain journal collections and budget for subscriptions (…).
-
Publishers can monitor their competitors, identify new publishing opportunities, and make decisions regarding current publications.
-
Editors can assess the effectiveness of editorial policies and objectives and track the standing of their journals.
-
Authors can identify journals in which to publish, confirm the status of journals in which they have published, and identify journals relevant to their research.
-
Information analysts (science policy makers) can track bibliometric trends, study the sociology of scholarly and technical publications, and analyse citation patterns within and between disciplines.
The importance and necessity of analytical citation tools like JCR is supported by the launch of alternative products like SCImago Journal & Country Rank and CWTS Journal Indicators, both attempting to compensate for the shortcomings of JCR or to include new features.
The growing availability of e-journals due to the advent of the internet and their increasing acceptance resulted in a rapid change in the user preference especially between 2001 and 2006, as reported in several studies (Kraemer, 2006; Schloegl and Gorraiz, 2010). As a result, usage metrics were reintroduced as an interesting alternative to citation metrics. Compared to the printed era, data collection is now much easier and faster, and usage metrics allow for viewing scholarly communication from the user's perspective.
The correlation between citation and usage data is highly dependent on the discipline's publication output and has been well documented in several studies (Bollen et al., 2005; Moed, 2005; Brody et al., 2006; Wan et al., 2008). Usage metrics can therefore be regarded as complementary to citation metrics; they reflect usage in a much broader scope (Duy and Vaughan, 2006) and have caused the emergence of the field of bibliometric research (Bollen and Van de Sompel, 2008; Schloegl and Gorraiz, 2009).
This paper suggests an approach to providing global usage metrics which is supported by libraries. The goal is to provide an analytical tool called Standardized Electronic Resource Usage Metrics (SERUM) which is comparable to the Journal Citation Reports (JCR), but which makes use of download data instead of citation data.
Citations metrics have a few well-known disadvantages. The most important ones are:
-
Citations are highly controversial. There are different reasons why authors cite others (objectivity vs. subjectivity; the problem of self-citations, citation networks, etc.).
-
Citations are only an indirect measure for impact, and no indication for quality.
-
Citations are always delayed. In some disciplines, half-lives cause citations to become significant only after long time spans.
-
Citations are simply insufficient in some fields. There are surprisingly low mean citation rates for the vast majority of published scholarly literature.
In comparison usage metrics overcome some of the disadvantages mentioned before:
-
Downloads are generally accepted as a proxy for usage.
-
Downloads are a direct measure and usage data can be recorded automatically.
-
Usage data can be accessed without delay.
-
Downloads are more suitable than citations in less publication- intensive fields.
There are of course known issues to be sorted out with usage data:
-
The availability of global usage data is restricted.
-
There is a risk of inflation by manual or automatic methods.
-
There are different access channels to scholarly resources (e.g. publisher sites vs. subject repositories vs. institutional repositories).
SERUM (Standardized Electronic Resource Usage Metrics), is an initiative which was suggested in response to the lack of globally available usage metrics for scholarly communication channels (primarily e-journals). Usage metrics definitely add a new dimension to existing quality criteria for scholarly journals, which are currently — apart from citation metrics — restricted to peer review, timeliness, editorial excellence, language and bibliographic information. As scholarly journals are still perceived as the most important scholarly communication channel, SERUM's initial focus is on the journal level.
The idea of SERUM is to combine the following three major features:
-
providing access to consolidated global usage data of e-journals;
-
establishing an international network of libraries that relates local usage trends to global usage data provided by the publishing houses;
-
offering services like ‘usable’ usage metrics and journal rankings (Figure 1).
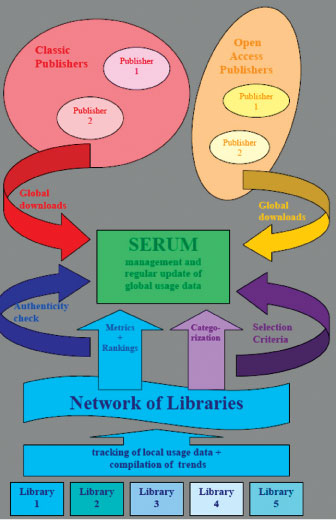
Figure 1: Schematic overview of SERUM.
In order to pave the way for SERUM it will be necessary to win over the publishers. Experience has shown that the big traditional publishers are more hesitant to cooperate than open access publishers. But both categories of publishers have a need to gather information about the usage of their products and track changes on the demand side of the market. Therefore publishers should be highly interested in the project since:
-
they would benefit from newly established evaluation criteria for periodicals beyond the JIF, and
-
a well-used initiative like SERUM would mean consequential strengthening of their products.
How is SERUM to work? Each publisher is invited to deliver usage data from as many titles per subject field as possible. The focus should of course be on top titles in terms of usage. From these titles, a network of libraries (see below) makes a selection of titles to be used in SERUM and for their categorisation using the most appropriate classification scheme.
The following data would be required (all at journal level) from the publishers:
-
total number of downloadable items per journal
-
number of downloadable items disaggregated (by document types) per journal
-
total download counts (full-text article requests — FTAs) for the current year (independent from the publication years of the journal)
-
download counts (full-text article requests — FTAs) for the current year with explicit listing of downloads per publication year of the journal for the last 5 years
-
download counts at journal level disaggregated by following document types: articles, review articles, proceedings papers, letters, notes
-
percentage of ‘non-downloaded’ items
-
distinction of downloads according to their origin (grouping by identical IP addresses without disclosing them) ↔ total view and geographical grouping (according to geographical distribution of the SERUM library network)
The following data could be provided optionally (all at journal level):
-
download counts (full-text article requests — FTAs) disaggregated by treatment or content (e.g., theoretical, methodological and experimental)
-
information about the distribution of downloads (how many articles (%) accumulate 75% of the total number of downloads, quantiles or quartiles)
-
total download counts (full-text article requests — FTAs) of the retrospective 1–5 years
-
distinction in regard to merits of the ‘downloads’: academic vs. non-academic, etc.
The data obtained would be consolidated and managed by the network of libraries and made accessible via a cooperative website offering further usage metrics and services based on these data (see below). This website will be primarily designed for journals analysis, but can of course be extended to serials and e-books later on. The outcome is a new instrument for the evaluation of electronic resources going beyond citations.
Single publishers are obviously not in the right position to deliver and manage overall global usage data obtained from multiple publishing houses. Moreover, suggested metrics and services should be provided by an independent, non-biased institution, as self-beneficial data manipulation by single publishers cannot be excluded. Therefore an international network should be established consisting of academic libraries with a sound disciplinary coverage and a significant geographical representation. This network would be responsible for fulfilling the following tasks:
-
implementation of the selection procedure for considered journal titles
-
categorisation of journals
-
management and regular update of global usage data either harvested from or delivered by publishers
-
introduction and promotion of usable metrics
-
provision of journal rankings
-
tracking of local usage data
-
authenticity check of global usage data based on local trends.
Several usage indicators have been suggested in recent years. Most suggestions are based on the classical citation indicators from the Journal Citation Reports (JCR), using download data (usually full-text article requests) instead of citations. The corresponding usage metrics are usage impact factor (UIF) (Rowlands and Nicholas, 2007; Bollen and Van de Sompel, 2008), usage immediacy index (Rowlands and Nicholas, 2007), download immediacy index (Wan et al., 2008), and usage half-life (Rowlands and Nicholas, 2007).
SERUM intends to develop a novel approach to usage metrics. Because the majority of downloads are made in the current and preceding year (Schloegl and Gorraiz, 2010), the classical immediacy index and the usage impact factor (UIF) seem to render less relevant results. Instead we suggest:
-
The journal usage factor (JUF) takes into account the reference year and the preceding two years. The JUF is defined as the number of downloads from journal items published in the current year and the previous two years divided by the number of items published in these three years. A three-year time window assures that a very significant number of downloads is covered in most cases.
-
The download immediacy (DI) will be measured as the percentage of articles downloaded in the current year in relation to the total amount of downloads.
-
The download half-life (DHL) is defined by the number of publication years from the current year that account for 50% of the downloads of the journal.
Further characteristics of the anticipated metrics in SERUM include:
-
Only downloads (full-text article requests — FTAs) will be considered, no visits or hits.
-
SERUM will operate at journal level and not at article level. SERUM will be designed as an instrument to reflect the usage characteristics of a journal as an entity. The four basic indicators are DT (total number of downloads), JUF, DI and DHL.
-
SERUM aims to disaggregate on the basis of document type (articles, review articles, proceedings papers, letters, notes and others); in other words, calculating JUF, DI, DHL for each document type.
-
If possible, SERUM also aims to disaggregate on the basis of treatment or content (e.g., theoretical, methodological and experimental) as well as in regard to the merits of the downloads (academic vs. non-academic).
-
SERUM's usage metrics will work at synchronic level (= downloads are tracked from one fixed year of documents issued in two or more publication years) as well as at diachronic level (= downloads are tracked from two or more years of documents issued in a fixed publication year). Also, all indicators will be calculated for the current and the previous two years, and the results will be compared.
-
According to the skewness distribution hypothesis of downloads at article level in a given journal, we are also interested in other distribution parameters, like the percentage of ‘non-downloads’, quantiles or quartiles.
-
All indicators will be calculated as weighted indicators on the basis of unique URLs, (the origin of downloads) in order to detect data manipulation.
-
Time lines and graphs will be provided for the most relevant indicators.
-
Increase/decrease rates will be analysed.
-
Once SERUM has been operational for a period of time, the metrics will be corrected in order to reflect usage practices and traditions in the different fields and disciplines. After establishing metrics for e-journals, corresponding metrics will be provided for e-books as the next logical step.
With the advent of the internet and the increased usage of e-journals, users of scholarly information migrated to the digital environment. As a consequence, ‘publishers have inherited all the knowledge of the user the librarian once had’ (Jamali et al., 2005). Libraries now depend on the usage data provided by the publishers.
Gathering local usage statistics is a cumbersome activity due to the technical requirements involved. Nevertheless the idea of comparing locally collected usage data to vendor-provided statistics was born seven years ago (Duy and Vaughan, 2003) and picked up by Coombs (2005). SERUM aims to revive this idea and build on the experience gained from previous studies as well as benefit from ongoing harmonisation and improved provision of vendor statistics as a result of COUNTER and SUSHI. Like MESUR, SERUM also aims to obtain usage data from the publishers in order to derive usage metrics from these. However, other than MESUR it is neither the objective of SERUM to create a complex semantic model of the scholarly communication process nor to produce science maps (Bollen et al., 2009) on the basis of the established reference data set. The maps and ranking services available from ‘MESUR: science maps and rankings from large-scale usage data’ are highly complex and only insightful for a minority of experts.
The unique aspects of SERUM will therefore be:
-
relating locally tracked usage data to global usage statistics provided by publishers (authenticity check)
-
strengthening the role of academic libraries by implementing the network with the suggested scope of duties
-
introducing new aspects in the evaluation of journals for all mentioned target groups (librarians, publishers, editors, authors, information analysts)
-
separating usage from citations
-
focusing on simplicity and usability.
Before all else, it is crucial to win over a few publishers. Large traditional publishers have already been approached on the subject and have either not responded or have refused their cooperation. As a consequence it was decided to address open access publishers instead to get the process started. Two large and one small OA publishers have responded positively and are willing to contribute to the SERUM project. The next step will be to share and discuss the data requirements and the feasibility of delivery.
Also, the idea of SERUM will be promoted amongst academic libraries (e.g. at conferences like LIBER) in order to identify potential partners for the network of libraries. Apart from the University Library of the Vienna University at least two further partners would be required for the pilot. Depending on the international reaction the requirements specification will be elaborated and a project plan designed.
Quite a few metrics initiatives have focused on usage data. However, so far none of them combined all the major features of SERUM, i.e., access to consolidated global usage data of e-journals; implementing an international network of libraries that relates local usage trends to global usage data provided by the publishing houses; offering services like ‘usable’ usage metrics and journal rankings.
Download statistics are not only relevant and necessary at the article level. The main scholarly communication channels themselves need to be measured, analysed and evaluated as entities (focus on journals, but also on monographs, etc.). Obviously, the prestige and eminence of journals is of major interest to many stakeholders in the process (librarians, publishers, editors, authors and information analysts).
Citations alone show only a part of the whole picture and are insufficient especially in the social sciences and in the arts & humanities. This is demonstrated by ERIH, (European Reference Index for the Humanities), a unique peer-review project in this discipline that aims to compensate for the unsatisfactory coverage of European humanities research in existing citation indices (AHCI, SSCI). However, this peer-review project is subject to continual revision and development, and support is highly expensive. Downloads would offer a more feasible alternative, but usable download metrics and services for a broad audience are not yet available (MESUR has a different scope).
At this point in time SERUM is only a ‘blue sky project’. Nevertheless its benefits are obvious and easy to summarise:
-
simplicity
-
comprehensibility
-
usability
-
fast and central availability.
|
Bollen, J., H. Van de Sompel, J.A. Smith and R. Luce (2005): ‘Toward alternative metrics of journal impact: a comparison of
download and citation data’, Information Processing and Management 41, 1419–1440;
http://public.lanl.gov/herbertv/papers/ipm05jb-final.pdf (accessed 1 July 2010).
|
|
Bollen, J. and H. Van de Sompel (2008): ‘Usage impact factor: the effects of sample characteristics on usage-based impact
metrics’, Journal of the American Society for Information Science and Technology, 59(1), 136–149.
|
|
Bollen, J., H. Van de Sompel, A. Hagberg, L. Bettencourt, R. Chute, M.A. Rodriguez and L. Balakireva (2009): ‘Clickstream
data yields high-resolution maps of science’, PLoS One 4(3), e4803, doi:10.1371/journal.pone.0004803.
|
|
Brody, T., S. Harnad and L. Carr (2006): ‘Earlier web usage statistics as predictors of later citation impact’, Journal of the American Society for Information Science and Technology, 57(8), 1060–1072.
|
|
Coombs, K.A. (2005): ‘Lessons learned form analyzing library database usage data’, Library Hi Tech, 23(4), 598–609.
|
|
Duy, J. and L. Vaughan (2003): ‘Usage data for electronic resources: a comparison between locally collected and vendor-provided
statistics’, The Journal of Academic Librarianship, 29(1), 16–22.
|
|
Duy, J. and L. Vaughan (2006): ‘Can electronic journal usage data replace citation data as a measure of journal use? An empirical
examination’, The Journal of Academic Librarianship, 32(5), 512–517.
|
|
Garfield, E. (1972): ‘Citation analysis as a tool in journal evaluation: Journals can be ranked by frequency and impact of
citations for science policy studies’, Science, 178(4060), 471–479.
|
|
Gross, P.L.K. and E.M. Gross (1927): ‘College libraries and chemical education’, Science, 66(1713), 385–389.
|
|
Jamali, H.R., D. Nicholas and P. Huntington (2005): ‘The use and users of scholarly e-journals: a review of log analysis studies’,
Aslib Proceedings : New Information Perspectives, 57(6), 554–571.
|
|
Kraemer, A. (2006): ‘Ensuring consistent usage statistics, part 2: working with use data for electronic journals’, The Serials Librarian, 50(1/2), 163–172.
|
|
Moed, H.F. (2005): ‘Statistical relationships between downloads and citations at the level of individual documents within
a single journal’, Journal of the American Society for Information Science and Technology, 56(10), 1088–1097.
|
|
Rowlands, I. and D. Nicholas (2007): ‘The missing link: journal usage metrics’, Aslib Proceedings : New Information Perspectives, 59(3), 222–228.
|
|
Schloegl, C. and J. Gorraiz (2006): ‘Document delivery as a source for bibliometric analyses: the case of Subito’, Journal of Information Science, 32(3), 223–237.
|
|
Schloegl, C. and J. Gorraiz (2009): ‘Global usage vs. global citation metrics using Science Direct pharmacology journals’,
Proceedings of the International Conference on Scientometrics and Informetrics, 1, 455–459.
|
|
Schloegl, C. and J. Gorraiz (2010): ‘Comparison of citation and usage indicators: the case of oncology journals’, Scientometrics, 82(3), 567–580.
|
|
Wan, J.-K., P.-H. Hua, R. Rousseau and X.-K. Sun (2010): ‘The download immediacy index (DII): experiences using the CNKI full-text
database’, Scientometrics, 82(3), 555–566.
|
COUNTER, Counting Online Usage of NeTworked Electronic Resources, http://www.projectcounter.org/
CWTS Journal Indicators, http://www.journalindicators.com/
ERIH, European Reference Index for the Humanities, http://www.esf.org/research-areas/humanities/erih-european-reference-index-for-the-humanities.html
MESUR, MEtrics from Scholarly Usage of Resources; http://www.mesur.org/
MESUR, science maps and rankings from large-scale usage data, http://www.mesur.org/services/
SCImago Journal & Country Rank, http://www.scimagojr.com/
SUSHI, Standardized Usage Statistics Harvesting Initiative, http://www.niso.org/workrooms/sushi